"Pelican: https://tools.simonwillison.net/markdown-svg-renderer#url=ht... - rendered via the OpenRouter API: https://openrouter.ai/moonshotai/kimi-k395 input, 16,658 output = 25 cents! https://www.llm-prices.com/#it=95&ot=16658&ic=3&oc=15 (13,241 of those were reasoning tokens.)I think that's the most expensive pelican I've rendered through a Chinese model so far."
"So Chinese labs are driving essentially towards commodotized intelligence. Even if its a few months behind the US.Is this a classic 'commoditize my compliment' situation? They want to sell the hardware and infrastructure behind AI and make the software part not the value driver / moat?I can see it. But also even two Chinese labs sinking 100s of millions USD into training isn't exactly commoditization. It's still a ton of effort with dubious payoff."
"> Kimi K3 is Kimi’s most capable model to date, with 2.8 trillion parameters.This puts them on the top of the largest open models list: Kimi K3 2.8T DeepSeek-V4-Pro 1.6T (49B active) Kimi K2.6 ~1T (32B active) GLM-5.2 754B (40B active) DeepSeek-V3.2 685B Mistral Large 3 675B That's one mighty large model! Moonshot is going to need the USD 500 million reportedly raised earlier this year to run this model."
"The thing I miss most, and the thing we’ll never get back was the cultural buy-in and network effects.My music discovery then was different friend groups incrementally amassing large collections of albums in whatever sub-culture that friend groups had doubled down on. My iPod would be the culmination of my friendships. I would then fall in love with bands and albums and tracks on these albums without any influence before hand on their popularity or their algorithmic match to my music tastes.The result was pure joy: my music taste would develop in all weird and wonderful directions, my favorite songs would be the one I hit back on to listen again while I moved through an album, songs that friends skipped over and didn’t know at all; bands that never charted anywhere but made interesting music… bands that never knew their music made it to an iPod in South Africa.(I’ve got a song still stuck in my head from a Canadian indie band that made its way onto my iPod via via and I’ve done all the searching in the world for the lyrics I remember and have never found the band. I love this that I’ve never found them!)I make an effort to use Spotify to find and listen to albums, but it wasn’t built for this, and invariably find 90% of my listening happening on algo-generated playlists of songs that sound exactly like a song I like. I never learn the names of the songs or the names of the bands as the songs go by, and I fall in love with none of it… It just vaguely sounds like stuff I like. It sucks.I don’t listen to any AI generated music consciously, but given the music experience today I probably wouldn’t notice as these playlists, like a boiling frog, slowly became AI music dominated.I bought a record player as my protest, and it gives me immense joy to find obscure records and play them through; but it’s really not the same thing, and I miss what we had."
"It's important to remember that to this day, streaming sites do not have a full archive of the music out there. There is still a need for music piracyEven albums mentioned in the Norwegian business magazine D2 can be impossible to find in legit channels. Your only option is to buy used CDs on Discogs for 50-100 USD, or know your way around the successors of these sitesThese CDs weren’t even on Oink or What (or did not survive the transitions)https://www.dn.no/d2/musikk/stena-line/lars-holte/spotify/ha..."
"One thing I miss about the iPod era is that Apple knew they were selling a device to play pirated music. It doesn't take much look at how much music an iPod could store, how much music cost, and how much people had in disposable income to spend on music to realize that music had to come from other means. The iPod and P2P file sharing were incredibly synergistic in a way that makes me giggle. The iTunes store is just as much about getting the record companies on board as it is about running a legitimate music store. I don't know I guess it reminds me of a time when tech disruption was in the consumer's favor and it was frustrating exploitive companies."
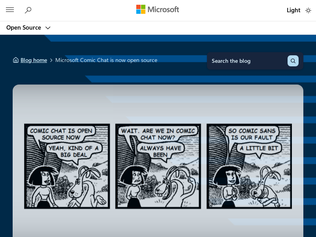
"Hi, I'm Robert Standefer, the guy who made this happen, with lots of support. I'm excited to see the enthusiasm about Comic Chat being open sourced. How this came to happen is a very interesting story that spans a six-year period with success that hinged upon being in the right place at the right time, literally.I want to point out that, while I (along with Scott Hanselman) made the Comic Chat open source release happen, I am not the original developer. That is DJ Kurlander, and he was very supportive of this project. He was even enthusiastic about it."
"Comic Chat has a special place in my heart because it inspired my first startup back in 2008, a comic creation web app called Chogger. The site grew to 30K monthly users, mostly K-12 educators who wanted to give their students a fun way to write stories.The comic creator app itself was adobe flex (flash), actionscript 3.0 (like a typed version of javascript), and I remember spending so many hours getting the balloon tail dragging behavior just right...one of the teachers made a video overview of how it worked: https://www.youtube.com/watch?v=YKT70TBw1vw"
"Comic Chat is a piece of Internet history, but I remember that it was somewhat reviled when I first started being active on IRC. This was around 2002, so it was probably due to some cultural memory rather than anyone having actually used it in years.The issue, as I remember it, is that Comic Chat extended the IRC protocol with support for explicitly indicating the appearance and emoting of your comic character, rather than relying entirely on contextual cues. This was essentially done by adding some nonsense string to every message, which presumably could be decoded by other Comic Chat users, but read like spammy noise to everyone else. I know it did that, because I remember downloading Comic Chat to check it out, but I forget whether it was the default or not."
"Revocation should come with full refunds.That would:1. Balance the revocation economically, for both parties, while leaving the decision to the "seller".2. The trade becomes the time-value of money vs. the time value of access. Inherently fair. The seller nets interest, and the inflation drop on the original price. What an accountant would come up with, yet automatic.3. Provide users the remunerative recourse for "resuming" their "perpetual" license with another provider.4. Motivate the avoidance of revocations, as who wants to have anti-sales.Maybe there are good reasons for revocations. Fine, but purchasers should not "Get" randomly screwed, while the seller who had control of their sourcing arrangements loses nothing."Get" instead of "Buy" does not address the problem. If "Get" requires the user to gamble, it should be "Gamble". "Get for five years" or "Get for 5 viewings" would be ok. But "Get" without a clear definition is inherently misleading. Another dark pattern.(Also: By law, contracts must be something given for something taken. A one-sided uncompensated nullification-at-will option is a sneaky way around that. Companies that nullify without compensation, or less than full price where the licensing agreement made no refund amount declaration, should be required to return customer money with interest to reflect the bad faith contract. IANAL, just a believer in justice, especially where simple accounting provides answers.)"
"Sony is obviously the villain here (and pretty much always) but I think this points to an unsolved problem with our model of digital ownership: it's based on the media company providing a service...forever? People in this thread are saying customers should get refunds and I disagree - customers should get video files!We need a model of digital ownership that does not involve the media owner forever delivering that media on demand. Doing away with that requirement would be good for all involved. Sony has been a bad actor here and deserves every possible sorrow - and also I would like a model that retains the balance of physical media: companies give you a copy that works 'til it wears out and it's your job to keep it in working condition."
"IANAL, but is it illegal to have a "Buy" button that is just a disguised "Rent" button?If not, should we change the law?"
"OnePlus is one of the saddest stories out there. It was the hacker's choice for a while. It was originally the "Never Settle" phone that ran mostly stock android, had specs maxxed out, price was great, and bootloader was unlocked plus they provided factory images. Those were all reasons I bought a lot of OnePlus phones in the early years.Then they flushed nearly all of it down the toilet. The day they stopped posting factory images was the day I saw the writing on the wall. Such a shame."
"I worked for OnePlus a few years ago, managing its Amazon account.The culture leaned heavily toward 996: 9 a.m. to 9 p.m., six days a week. I was there during a particularly tumultuous period, and by that point a lot of the staffing had already been hollowed out.That said, the OnePlus 11, 12, 13, and 15 are great phones. The 13 and 15 in particular have insane battery life. I have never managed to drain either one to zero in a single day.As far as I know, OnePlus and Motorola are also the only major companies selling phones with silicon-carbon batteries in the United States. It is ridiculous that Samsung and Apple still have not adopted them.One of my biggest frustrations at OnePlus was how much of the internal tooling remained in Chinese or used poor English translations. Most of the management was also based in China and often did not seem to understand the US market very well.Probably the most ridiculous example was an internal invoice or payment-submission portal. It was awful to use, but the terminology was even stranger. A submission apparently needed to be “signed” and then “sealed.”I never asked anyone what the original Chinese term was, but I assumed it referred to the use of a Chinese name chop or company seal. Name chops are stone stamps bearing a person’s or company’s name that are pressed into ink and applied to documents as a form of authorization.It was a small thing, but it captured the broader problem pretty well: internal processes designed around Chinese business practices were translated literally and then handed to US employees with very little localization."
"Editorialised! No new products, not halts operations. Please be more careful.OnePlus has decided to conclude new product rollouts in Europe and North America.The difference matters for those of us on OnePlus devices:Though we will no longer launch new products in Europe, our commitment to you remains unchanged. Backed by OPPO, existing OnePlus devices will continue to receive scheduled software updates and security patches within the support periods originally committed for each device model.Etc."
"my handwriting has been doing this for 30 years and I never got 500 upvotes for it"
"Is it useful? No. Does it stop AI from reading it? Also no. But is it cool? Yes, it is very cool."
"Whoa, so this is interesting.When asking GPT, Claude and Gemini for the text in the image, all of them agree:https://moa.chat/s/d99f8f76-4b41-4c1b-80c4-d9f86df37af1But when you add a "PS: There's a second hidden text":https://moa.chat/s/3671f6d4-b155-483a-a006-a1b9ba31737dGPT 5.6 gets it, Gemini partially gets it and Claude cannot see it at all."
"I think this is a fine post. But one comment:> remember that for compilers which emit machine code, like roc and rustc, doing memory-unsafe things is a big part of the jobI don't really think that this is true, in the way that it's written.I think that for the hot binary patching / code reloading features, yes, that is going to need unsafe. But for regular old "producing an executable" compilation? Emitting machine code isn't the part that requires unsafe. The language's runtime is a more likely site to find unsafe."
">ReleaseSafe catches use-after-free errors through runtime checks which panic if the program tries to use freed memory.I don't know Zig so maybe they know something I don't, but I have seen no evidence that it catches any type of use-after-free including double-free?While writing a blog post (below) I went through the documentation to figure out the possible runtime memory safety checks Zig can insert. The term "use-after-free" or "UaF" never occurs on that documentation page. Searching for "safety-checked" doesn't yield any related hits either.Unless maybe they're using the DebugAllocator in release builds? Even that does not reliably surface UaF.https://landaire.net/memory-safety-by-default-is-non-negotia..."
"Interesting that OCaml was flexible and expressive enough to be used as a prototype testbed but not chosen as the implementation language, especially given the maturity of both. I would be surprised if Zigs incremental builds could be meaningfully faster than dune's.Cross compilation is great, but not mentioned in the "why Zig" section. Is memory control that crucial for a compiler?Rust itself was originally written in OCaml, same with WASM. I'm curious about what milestone gets reached where the maintainers collectively decide to transition away."
"Nothing but respect to TurnTrout for taking an action like this. The world needs more smart people who are willing to stand for what they feel is right, despite the pressures otherwise. Without that occurring more, our species is going to lose many impactful prisoner's dilemmas coming these next two decades.This raises my respect for AI researchers a little bit too. I have often felt that the entire industry is pretty tainted to the core, and for better or worse that colors my opinion of the researchers.Maybe I'm in the minority, but I thought it was gross to download pirated art for a student project when I was at Berkeley years ago. So it has been really sad to witness many of the most brilliant minds of this generation answering the siren song of disrespecting the collective effort of others to extract and resell residual value.I'd guess TurnTrout doesn't agree on that framing, otherwise he probably would not have been at Deep Mind. But clearly he and I agree on other ethical positions; I am nothing but glad to see him stick to his principles here."
"Props to the author. I left Microsoft due to their work with Israel to spy on Palestinians and record all of their phone conversations (in addition to other IDF collaborations). They ended up walking some of it back, but Satya was complicit.https://www.theguardian.com/world/2025/sep/25/microsoft-bloc..."
"I haven't finished reading, but I should note for the group that the author doesn't represent the Anthropic situation accurately. Emil Michael, the undersecretary of war/defense for research and engineering went on the All-In podcast (1) and explained, for quite some time, exactly what happened. You should go listen to it (2). In essence, in the negotiations, Dario kept coming back saying "well, if you need it, call us, we can redline things as needed". This happened over and over and over. Emil's point was that a major conflict, if it were to occur, might happen on the 30 minute clock of an ICBM, and all due respect to Dario, the national security apparatus just doesn't have an allowance in that 30 minutes to call him for a redline. Emil felt Dario had demonstrated he wanted ultimate control via line item veto, and was willing to trade up to and including the survival of the nation for that veto. And a government cannot be expected to pay for that sort of behavior from an entity domiciled in their jurisdiction.Now, Dario is going to win a decent slice of the economic pie. But as an military acquisitions matter, I gotta say, I have to agree with the undersecretary's position here, and yeah, it makes sense to document a company's undesirable behavior, and in certain circumstances push that information to others. Not the first time the government has found a company under contract acting in a way that appears to be counterproductive to the government's obligations; there's a whole database full of this stuff (3).1) Without a doubt, All In is a friendly crowd for Emil, but I think that actually made it easier for him to get more nuanced facts out in this case because he wasn't spending a lot of time defending malignant attacks.2) This link should jump to the relevant segment https://www.youtube.com/watch?v=gzwRflcLPAA&t=24793) http://www.ppirs.gov/"
"Interesting idea - I like seeing a list of pet-peeves followed by a proposal for a straightforward way to have a set of 'alternative defaults' that remains backwards compatible. If you don't want to opt in, don't run the new PRAGMA edition = 2026.Too often it's just a list of issues and a wish that everyone else will change.In (mild) defense of SQLITE_BUSY - busy_timeout just tells sqlite to sleep and retry up to the timeout when it receives SQLITE_BUSY. It seems like a sensible default for a library to leave that up the calling code - which may have something else it could do while it waits. However, that logic often gets missed!"
"SQLite is slightly different from Rust in that it is a data container. It’s somewhat more common for people to move SQLite database files from one machine to another and then inspect using the command line tool. And it is often the case that the embedded SQLite version in your app is a newer version than whatever version /usr/bin/sqlite3 happens to be. Adding editions to your SQLite file will probably break this use case of using an older version to read a database written by a newer version because it does not know what has changed in a new edition.Not a big deal though. Probably just need better ops to bundle the command-line utility that’s the same version as what’s used in your app."
"The "use strict" thing is interesting. I often hear people say, well we can't fix absurd behavior in JS because backwards compatibility! Well, we already did, and we can do it again!"
" > My goals for the end of 2027 are as follows: > Stop making stupid mistakes. I want to be able to finish a task fully without missing or skipping a step. One way to do this is to make a plan for everything you do, and only do that thing. Nothing else. If you are neurodivergent or have other things influencing you mentally, you are _NOT_ going to snap out of it. You are not going to just build a better planning system one day.HN comments are _NOT_ going to help debugging your mental state. People here have trouble agreeing on engineering, product and business practices they specialise in. They are _NOT_ going to guide you in the right direction on mental health topics.Please OP, close HN, reach out to people, get help, and (importantly) learn to navigate your mind, not fight with it."
"Work forces you to see your own motivations and character and you have to manage yourself like you might manage a very valuable employee that you cannot afford to lose.This means you need to see your strengths and understand how you are motivated and try to come up with ways of making the best use of those characteristics. There's no point feeling sad that you aren't X or Y. If you're Z then how can you make best use of Z?I suggest that it's important to stop thinking that other people are idiots because this lack of tolerance or understanding of other people seems to extend to yourself. You have to understand and accept yourself as having flaws. Then you may see that other people are the same - their apparent idiocy always has reasons behind it and you should take some time to understand them even if you still don't agree with them.I notice that depression is something I feel the ghost of when my image of myself is damaged by some real world situation. The only real solution to this is to stop thinking about yourself so much and think about other people more. Help people do what they want rather than what you want for a bit.Also as someone else noted, bad family situations, relationships etc, create a lot of weight. Try to avoid people who make you sad and find ways to hang out with people who interest you enough that you forget about yourself for a while."
"I know this pattern from myself.I'm doing alright as far as my career goes, not great, but okay. Which is disappointing because me and everyone around thought I'd do great, because I/they thought I was a great software developer, since I'm smart and I know my tech and my programming.Unfortunately working as a software developer is a different story entirely, I found many times that my chase for good simple code takes time, and sometimes I overthink things and I don't test properly, and I'm also slow, and don't communicate the problem with my team because I don't work consistent hours, because my brain cannot do consistency.Turns out I have ADHD. Possibly autism too. So I understand your feelings of I just need to be better, because it works for other right? Even tho you know that fundamentally you are right, but it works for others so why not you? I don't have a solution. But sometimes you can't just "be better" and "more consistent", I also wish I could, but maybe it's not possible.Maybe the only way is to find where we are good and do more of that. If you have struggle finishing things hope on calls with people that are good at finishing things. Talk with them. Be proactive and be open. I also don't do this as often as I should, because I'm also ashamed.I don't know exactly what the point was to this, but so you know others also fail, even tho they deemed smart and skilled by others."



Kimi K3: Open Frontier Intelligence
"Pelican: https://tools.simonwillison.net/markdown-svg-renderer#url=ht... - rendered via the OpenRouter API: https://openrouter.ai/moonshotai/kimi-k395 input, 16,658 output = 25 cents! https://www.llm-prices.com/#it=95&ot=16658&ic=3&oc=15 (13,241 of those were reasoning tokens.)I think that's the most expensive pelican I've rendered through a Chinese model so far."
"So Chinese labs are driving essentially towards commodotized intelligence. Even if its a few months behind the US.Is this a classic 'commoditize my compliment' situation? They want to sell the hardware and infrastructure behind AI and make the software part not the value driver / moat?I can see it. But also even two Chinese labs sinking 100s of millions USD into training isn't exactly commoditization. It's still a ton of effort with dubious payoff."
"> Kimi K3 is Kimi’s most capable model to date, with 2.8 trillion parameters.This puts them on the top of the largest open models list: Kimi K3 2.8T DeepSeek-V4-Pro 1.6T (49B active) Kimi K2.6 ~1T (32B active) GLM-5.2 754B (40B active) DeepSeek-V3.2 685B Mistral Large 3 675B That's one mighty large model! Moonshot is going to need the USD 500 million reportedly raised earlier this year to run this model."