17 July 2026



16 July 2026


15 July 2026


14 July 2026

13 July 2026

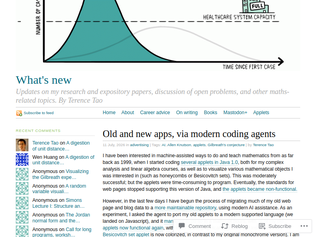
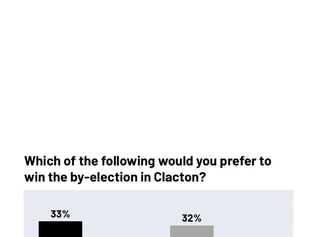
12 July 2026






11 July 2026

![Preview of 'GPT-5.6 Sol Ultra produces proof of the Cycle Double Cover Conjecture [pdf]'](default_48863490.png)


10 July 2026





09 July 2026


08 July 2026


![Preview of 'A better way to tie gym shorts (or any drawstring) [video]'](default_48816956.png)
Kimi K3: Open Frontier Intelligence
"Pelican: https://tools.simonwillison.net/markdown-svg-renderer#url=ht... - rendered via the OpenRouter API: https://openrouter.ai/moonshotai/kimi-k395 input, 16,658 output = 25 cents! https://www.llm-prices.com/#it=95&ot=16658&ic=3&oc=15 (13,241 of those were reasoning tokens.)I think that's the most expensive pelican I've rendered through a Chinese model so far."
"So Chinese labs are driving essentially towards commodotized intelligence. Even if its a few months behind the US.Is this a classic 'commoditize my compliment' situation? They want to sell the hardware and infrastructure behind AI and make the software part not the value driver / moat?I can see it. But also even two Chinese labs sinking 100s of millions USD into training isn't exactly commoditization. It's still a ton of effort with dubious payoff."
"> Kimi K3 is Kimi’s most capable model to date, with 2.8 trillion parameters.This puts them on the top of the largest open models list: Kimi K3 2.8T DeepSeek-V4-Pro 1.6T (49B active) Kimi K2.6 ~1T (32B active) GLM-5.2 754B (40B active) DeepSeek-V3.2 685B Mistral Large 3 675B That's one mighty large model! Moonshot is going to need the USD 500 million reportedly raised earlier this year to run this model."