This article will dive into the system behind the generation of Hacker News Daily, an open source lightweight daily Hacker News best stories website, with screenshots and top comments.

Motivation
Hacker News is my go-to source for relevant, interesting and constructive discussions on a wide range of topics. I usually consume it via Daemonology’s Hacker News Daily, to catch up on the most active topics in the community.
Daemonology’s Hacker News Daily presents the title, story link, Hacker News discussion link, and is optimized for desktop. I usually consult it on mobile, and when I am several days behind, I sweep through the archives and open several story/discussion links in separate mobile tabs, in order to triage the stories with a quick glance at their web page and their discussion’s top comments.
This project aims to ease that process, by generating a set of web pages presenting the best daily Hacker News for mobile or desktop, with screenshots and top comments for each story, while aiming to have a low footprint to the end user.
Architecture
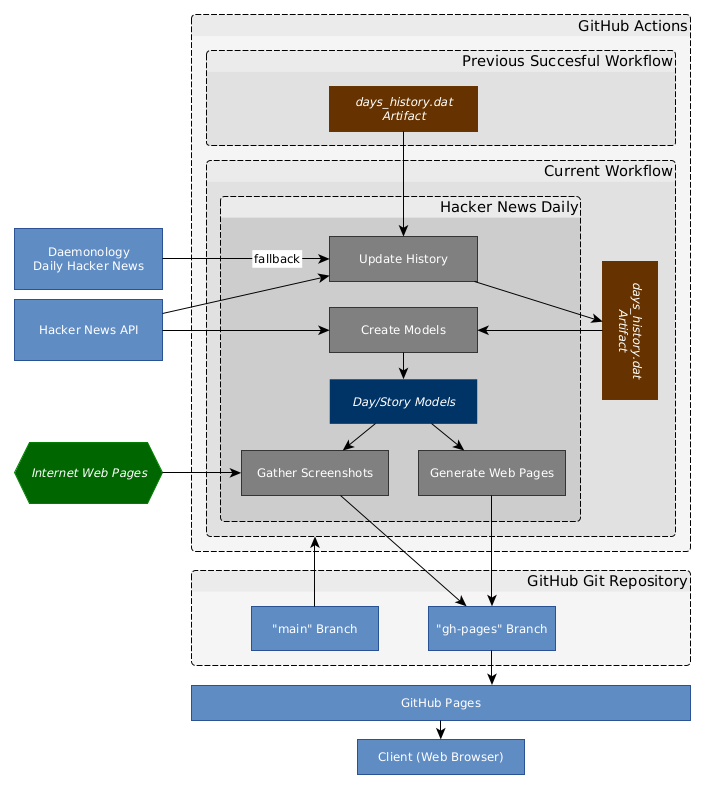
The basilar idea is to recurrently get the best Hacker News stories via its API; take screenshots of the web pages that these stories link to; and have this workflow executed via GitHub Actions.
In specific, these are the steps taken to generate the final web pages (illustrated by the above diagram):
1. Every day, a new Github Workflow is spawned, kickstarting the entire process.
2. Update History
- The first step is to get the past days best stories from the last successful run, and add the current best stories by
reaching out to the Hacker News API to fetch the current list of best stories, removing the ones that were already featured, and adding the top ones to the current history
- To persist the past best stories history, an
days_history.datartifact is created in every run, which is a simple Python Pickle containing the story ids from the past days. These days are stored in form of a deque, in order to pop the older days as the history grows larger - The final result of this step is a new
days_history.dat, which will be used in the next step below, and will also serve as a base for the next workflow - If a viable
days_history.datartifact cannot not be found in the previous successful runs, it is rebuilt by parsing the Daemonology’s Hacker News Daily web page
- To persist the past best stories history, an
3. Create Day/Story Models
- From the story ids provided by the previously built
days_history.dat, a list of hydrated days with their respective stories are built. These models will posteriorly provide all the information needed to create the final web page views- Each story is composed of an ID, title, story link, Hacker News discussion link, and its top comments. This information is obtained via the Hacker News API (example call)
4. Create the generated folder. This is where the generated web pages and screenshots will be placed, in order to be later deployed to GitHub pages
5. Gather Screenshots
- Using pyppeteer, an headless browser is created to navigate through all the story links
- A screenshot is taken for each of these pages (after attempting to dismiss a possible “Allow Cookies” prompt), and stored as PNGs in the
generatedfolder - Each of these screenshots are re-encoded in WebP, which allows for a smaller image footprint in browser’s that support it
- A screenshot is taken for each of these pages (after attempting to dismiss a possible “Allow Cookies” prompt), and stored as PNGs in the
- If there is an unexpected error while processing the screenshots, it will not halt the overall workflow, since the final web pages can still function without screenshot images
6. Generate Web Pages
- Jinja, a templating engine for Python, is used to define and generate each of the final web pages. Four web pages are generated from a single template. These four variants are permutations of either presenting all past 10 days or not, and either showing images or not:
- Latest day, with images
- Latest day, without images
- Past 10 days, with images
- Past 10 days, without images
- It was chosen to keep these in separate static web pages, in order to keep them simple, static, and without additional dynamic logic
7. The generated folder is deployed to the gh-pages branch, which is deployed as a GitHub page, making these generated contents publicly accessible
Source Code
The full source code is accessible at https://github.com/lopespm/hackernews_daily and the generated website at https://lopespm.github.io/hackernews_daily, feel free to improve it or to leave some feedback.